




Authors: Iresh Sharma & Mridul Ganga
What is WebRTC?
WebRTC stands for web real-time communication, it is an open standard for real-time communications over the internet. With Webrtc you can implement realtime video, voice and data transfer between various peers, this technology is available for almost any browser and provides native clients for most platforms including android and iOS.
What can we do with WebRTC?
The application of WebRTC can range from anywhere between a simple chatting application, to full-fledged audio and video conferencing applications, file transfer applications etc.
How do things work?
Behind the scenes WebRTC is a pretty complex technology, given the scope of this article, we would talk only about the basic terminology, i.e, the things you’d definitely need to know when you start with webRTC.
Peer to Peer connections
Two peers transfer information with each other without involvement of a server. webRTC has many implementations but realtime p2p video and audio (multimedia connection) are the most widely used. We will talk about how it happens below.
STUN Servers
Stun stands for Session Traversal of User Datagram Protocol [UDP] Through Network Address Translators [NATs]. To understand what stun is and how it works, we need to know more about NAT and the way web servers send data back to our machines.
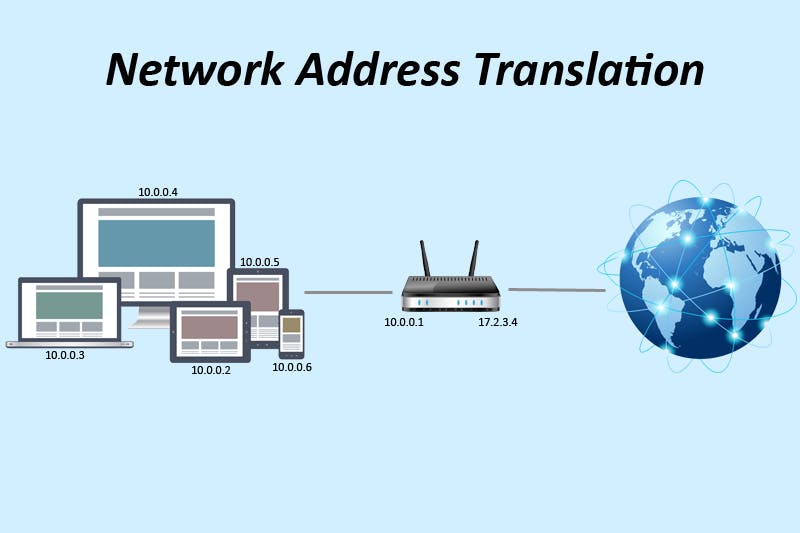
NAT
Network Address Translator. The number of devices connected to the internet are far more than the available IP addresses. To deal with this problem, NAT was introduced. The NAT is part of a router. Each router has a single public IP and can have multiple devices connected to it. All the devices are assigned a private IP using DHCP or manually. These private IPs are not accessible from the internet. To reach the devices under a NAT, the sender must use the public IP of the router along with a PORT. This port helps the router figure who the receiver is.
Example -
A device joins a router network and gets a private IP 10.0.0.2 The router internally makes a NAT Table with an entry for the device private IP and external router port mapping
Device 1 (device) - 10.0.0.2 (private ip) - 27098 (public port)
The router has a public IP 15.10.20.30
Now, if we want to access device 1 from the internet, we will use the IP - 15.10.20.30 and the port 27098. This request will arrive at the router and router will goto the NAT table and find the port, where we will get the private IP of the device 1. So the router will forward the request to device 1.
NAT Traversal
Imagine there are two devices using their own routers. Both will be under a NAT layer. The device 1 under router 1 wants to reach the device 2 under router 2. To do this, we should make a route like the following.
Device1 (private ip) -> router1 (public ip and port) -> router2 (public ip and port) -> device 2 (private ip)
The above route is how our data will traverse the multiple NAT layers of the internet. This process is done internally by our browsers and routers and other network devices on the internet.
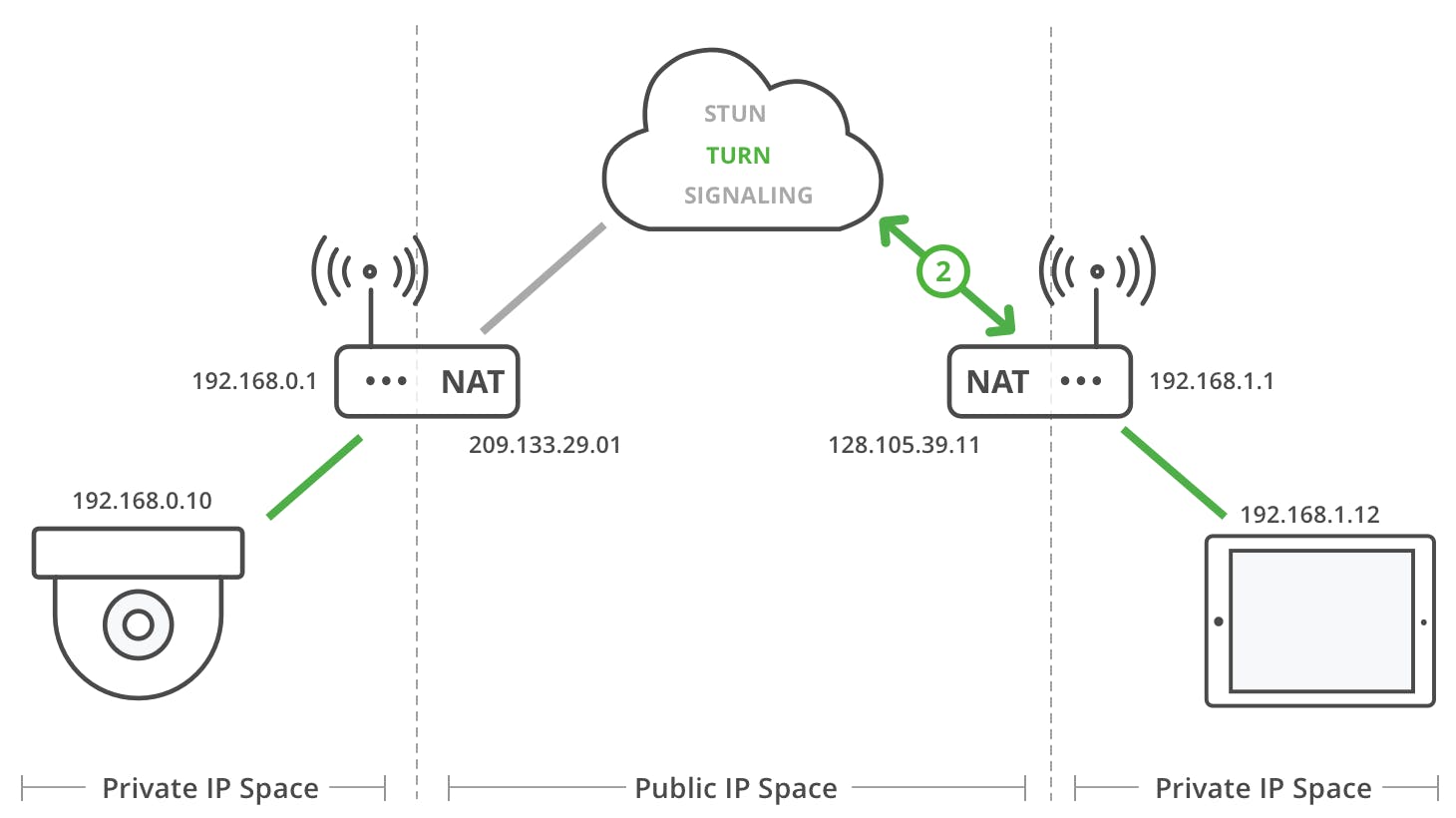
How STUN uses NAT Traversal?
The STUN server is a publicly hosted server. When a peer makes a request to the STUN server, the stun server gets to know the path that the data will follow to reach the peer. It returns this path (public address of the peer) back to the peer. So, now the peer is aware of the path using which it can be accessed from anywhere on the internet. The peer can later send others this path and establish a P2P connection.
TURN Server
TURN stands for Traversal Using Relay NAT. We looked at how STUN works. In case of TURN, we have a public TURN server which acts as a relay. We do not send the data directly between the peers, but rather through the TURN server. Device 1 wants to send data to Device 2. It will contact the TURN server with the data and address of device 2. The TURN server will then forward the request to the device 2. TURN server is used for more secure data connections and there is less chance of data loss as compared to the STUN server. TURN can be used for file and information transfer whereas STUN is used for lossy audio and video transfers.
Signaling
To initiate communication between two peers, we need a middleware signaling server. We share information i.e. Offer and Answer which are SDP (Session Description Protocol) explained below. Peer A sends an offer to Peer B using a signal channel. Peer B receives the offer and sends an Answer to Peer A using the signal channel.
Session Description
The session description has the configuration of the peer (webrtc endpoint). It has information like - media type, format, transfer protocol, endpoint address (IP, PORT) etc. This information is transferred using the SDP. During signaling Peer A creates a SD called offer which is sent to Peer B. Peer B creates a SD called answer and sends it back to Peer A. This way both peers share information needed to exchange media and data. This transfer of data is handled using ICE (Interactive Connectivity Establishment) - more about this below. After this, each peer keeps a local (itself) and remote (peer b) description.
ICE
ICE stands for Interactive Connectivity Establishment. This is used to share network related information which intern is used for the NAT traversal. This is used to define and use the NAT traversal path which will be used to transfer data between two peers.
ICE Candidates
Peer must exchange information about network connection to transfer data. There may be one or more routes to a peer, these are ICE candidates. ICE candidates have details of the available methods that can be used to connect to a peer. The peer proposes its best candidate first going to the worst candidate. The candidates can be UDP or TCP, but UDP is normally used, as it is faster and the media can recover from interruptions easily.